Bei der statistischen Modellierung ist die Regressionsanalyse eine Studie, mit der die Beziehung zwischen Variablen bewertet wird. Diese mathematische Methode umfasst viele andere Methoden zum Modellieren und Analysieren mehrerer Variablen, wenn der Schwerpunkt auf der Beziehung zwischen der abhängigen Variablen und einer oder mehreren unabhängigen Variablen liegt. Insbesondere hilft die Regressionsanalyse zu verstehen, wie sich ein typischer Wert einer abhängigen Variablen ändert, wenn sich eine der unabhängigen Variablen ändert, während die anderen unabhängigen Variablen fest bleiben.

In allen Fällen ist die Zielschätzung eine Funktion unabhängiger Variablen und wird als Regressionsfunktion bezeichnet. In der Regressionsanalyse ist es auch von Interesse, die Änderung der abhängigen Variablen als Funktion der Regression zu charakterisieren, die mit einer Wahrscheinlichkeitsverteilung beschrieben werden kann.
Aufgaben der Regressionsanalyse
Diese statistische Untersuchungsmethode wird häufig für Prognosen verwendet, bei denen ihre Verwendung einen erheblichen Vorteil hat. Manchmal kann sie jedoch zu Illusionen oder falschen Beziehungen führen. Daher wird empfohlen, sie in dieser Ausgabe sorgfältig zu verwenden, da Korrelation beispielsweise keinen Kausalzusammenhang bedeutet.
Für die Durchführung von Regressionsanalysen wurde eine Vielzahl von Methoden entwickelt, beispielsweise die lineare und die gewöhnliche Regression kleinster Quadrate, die parametrisch sind. Ihre Essenz ist, dass die Regressionsfunktion als eine endliche Anzahl unbekannter Parameter definiert ist, die aus den Daten geschätzt werden. Die nichtparametrische Regression ermöglicht, dass ihre Funktionen in einem bestimmten Satz von Funktionen liegen, die unendlich dimensional sein können.
Als statistische Untersuchungsmethode hängt die Regressionsanalyse in der Praxis von der Form des Datenerzeugungsprozesses und seinem Zusammenhang mit dem Regressionsansatz ab. Da die wahre Form des Datenprozesses in der Regel eine unbekannte Zahl generiert, hängt die Regressionsanalyse der Daten häufig in gewissem Maße von den Annahmen über diesen Prozess ab. Diese Annahmen werden manchmal überprüft, wenn genügend Daten verfügbar sind. Regressionsmodelle sind oft nützlich, selbst wenn Annahmen mäßig verletzt werden, obwohl sie nicht mit maximaler Effizienz funktionieren können.
Im engeren Sinne kann sich die Regression im Gegensatz zu den in der Klassifizierung verwendeten diskreten Antwortvariablen speziell auf die Bewertung kontinuierlicher Antwortvariablen beziehen. Der Fall einer kontinuierlichen Ausgabevariablen wird auch als metrische Regression bezeichnet, um sie von verwandten Problemen zu unterscheiden.
Die Geschichte
Die früheste Form der Regression ist die bekannte Methode der kleinsten Quadrate. Es wurde 1805 von Legendre und 1809 von Gauß veröffentlicht. Legendre und Gauß wandten die Methode an, um aus astronomischen Beobachtungen die Umlaufbahnen von Körpern um die Sonne (hauptsächlich Kometen, aber später neu entdeckte Kleinplaneten) zu bestimmen. Gauß veröffentlichte 1821 eine Weiterentwicklung der Theorie der kleinsten Quadrate, einschließlich einer Version des Gauß-Markov-Theorems.

Der Begriff „Regression“ wurde im 19. Jahrhundert von Francis Galton geprägt, um ein biologisches Phänomen zu beschreiben. Das Fazit war, dass das Wachstum der Nachkommen aus dem Wachstum der Vorfahren in der Regel auf den normalen Durchschnitt zurückgeht.Für Galton hatte die Regression nur diese biologische Bedeutung, aber später wurde seine Arbeit von Udney Yule und Karl Pearson fortgesetzt und in einen allgemeineren statistischen Kontext gebracht. In der Arbeit von Yule und Pearson wird die gemeinsame Verteilung von Antwortvariablen und erklärenden Variablen als Gauß'sch angesehen. Diese Annahme wurde von Fisher in den Werken von 1922 und 1925 abgelehnt. Fisher schlug vor, dass die bedingte Verteilung der Antwortvariablen Gauß'sch ist, die gemeinsame Verteilung jedoch nicht. In dieser Hinsicht ist Fischers Annahme näher an der Gauß-Formulierung von 1821. Bis 1970 dauerte es manchmal bis zu 24 Stunden, um das Ergebnis einer Regressionsanalyse zu erhalten.

Regressionsanalysemethoden sind weiterhin ein Bereich der aktiven Forschung. In den letzten Jahrzehnten wurden neue Methoden für eine zuverlässige Regression entwickelt. Regression mit korrelierten Antworten; Regressionsmethoden, die verschiedene Arten fehlender Daten berücksichtigen; nichtparametrische Regression; Bayesianische Regressionsmethoden; Regressionen, bei denen Prädiktorvariablen mit einem Fehler gemessen werden; Regressionen mit mehr Prädiktoren als Beobachtungen sowie kausale Rückschlüsse auf die Regression.
Regressionsmodelle
Regressionsanalysemodelle umfassen die folgenden Variablen:
- Unbekannte Parameter, die als Beta bezeichnet werden und ein Skalar oder Vektor sein können.
- Unabhängige Variablen, X.
- Abhängige Variablen, Y.
In verschiedenen Bereichen der Wissenschaft, in denen die Regressionsanalyse angewendet wird, werden anstelle von abhängigen und unabhängigen Variablen verschiedene Begriffe verwendet, aber in allen Fällen bezieht sich das Regressionsmodell auf die Funktionen X und β.
Die Näherung hat normalerweise die Form E (Y | X) = F (X, β). Um eine Regressionsanalyse durchzuführen, muss die Art der Funktion f bestimmt werden. Seltener basiert es auf der Kenntnis der Beziehung zwischen Y und X, die nicht auf Daten beruht. Wenn ein solches Wissen nicht verfügbar ist, wird eine flexible oder zweckmäßige Form F gewählt.
Abhängige Variable Y
Angenommen, der Vektor unbekannter Parameter β hat die Länge k. Um eine Regressionsanalyse durchzuführen, muss der Benutzer Informationen zur abhängigen Variablen Y bereitstellen:
- Wenn es N Datenpunkte der Form (Y, X) gibt, bei denen N
- Wenn genau N = K beobachtet wird und die Funktion F linear ist, kann die Gleichung Y = F (X, β) genau und nicht näherungsweise gelöst werden. Dies reduziert sich auf die Lösung eines Satzes von N-Gleichungen mit N-Unbekannten (Elementen von β), die eine eindeutige Lösung haben, solange X linear unabhängig ist. Wenn F nicht linear ist, existiert die Lösung möglicherweise nicht oder es existieren möglicherweise viele Lösungen.
- Am häufigsten ist die Situation, in der N> Punkte auf die Daten beobachtet werden. In diesem Fall sind in den Daten genügend Informationen vorhanden, um den eindeutigen Wert für β zu bewerten, der am besten mit den Daten übereinstimmt, und das Regressionsmodell kann, wenn es auf die Daten angewendet wird, als überbestimmtes System in β betrachtet werden.
Im letzteren Fall bietet die Regressionsanalyse Tools für:
- Finden von Lösungen für unbekannte Parameter β, die zum Beispiel den Abstand zwischen den gemessenen und vorhergesagten Werten von Y minimieren.
- Unter bestimmten statistischen Annahmen verwendet die Regressionsanalyse überschüssige Informationen, um statistische Informationen über unbekannte Parameter β und die vorhergesagten Werte der abhängigen Variablen Y bereitzustellen.
Notwendige Anzahl unabhängiger Messungen
Betrachten Sie ein Regressionsmodell mit drei unbekannten Parametern: β0, β1 und β2. Angenommen, der Experimentator führt 10 Messungen mit demselben Wert der unabhängigen Variablen des Vektors X durch.In diesem Fall liefert die Regressionsanalyse keine eindeutigen Werte. Das Beste, was Sie tun können, ist, den Mittelwert und die Standardabweichung der abhängigen Variablen Y auszuwerten. Indem Sie zwei verschiedene X-Werte auf dieselbe Weise messen, können Sie genügend Daten für eine Regression mit zwei Unbekannten erhalten, jedoch nicht für drei oder mehr Unbekannte.

Wenn die Messungen des Experimentators bei drei verschiedenen Werten der unabhängigen Variablen des Vektors X durchgeführt wurden, liefert die Regressionsanalyse einen eindeutigen Satz von Schätzungen für drei unbekannte Parameter in β.
Bei der allgemeinen linearen Regression entspricht die obige Aussage der Anforderung, dass die Matrix X istTX ist reversibel.
Statistische Annahmen
Wenn die Anzahl der Messungen N größer ist als die Anzahl der unbekannten Parameter k und der Messfehler εichIn der Regel wird dann der in den Messungen enthaltene Informationsüberschuss verteilt und für statistische Vorhersagen über unbekannte Parameter verwendet. Dieser Informationsüberschuss wird als Grad der Regressionsfreiheit bezeichnet.
Grundlegende Annahmen
Klassische Annahmen für die Regressionsanalyse sind:
- Die Stichprobe ist repräsentativ für die Inferenzvorhersage.
- Der Fehler ist eine Zufallsvariable mit einem Durchschnittswert von Null, der von den erklärenden Variablen abhängig ist.
- Unabhängige Variablen werden fehlerfrei gemessen.
- Als unabhängige Variablen (Prädiktoren) sind sie linear unabhängig, dh es ist nicht möglich, einen Prädiktor in Form einer linearen Kombination der anderen auszudrücken.
- Fehler sind nicht korreliert, d. H. Die Kovarianzmatrix von Diagonalfehlern und jedes Nicht-Null-Element ist die Varianz des Fehlers.
- Die Varianz des Fehlers ist gemäß den Beobachtungen konstant (Homoskedastizität). Andernfalls können Sie die Methode der gewichteten kleinsten Quadrate oder andere Methoden verwenden.
Diese ausreichenden Bedingungen für die Schätzung der kleinsten Quadrate besitzen die erforderlichen Eigenschaften, insbesondere bedeuten diese Annahmen, dass die Parameterschätzungen objektiv, konsistent und effektiv sind, insbesondere wenn sie in der Klasse der linearen Schätzungen berücksichtigt werden. Es ist wichtig zu beachten, dass Beweise selten die Bedingungen erfüllen. Das heißt, die Methode wird auch dann verwendet, wenn die Annahmen nicht zutreffen. Eine Variation von Annahmen kann manchmal als Maß dafür verwendet werden, wie nützlich dieses Modell ist. Viele dieser Annahmen können durch fortgeschrittenere Methoden gemildert werden. Statistische Analyseberichte enthalten in der Regel die Analyse von Tests auf der Grundlage von Probendaten und der Methodik für den Modellnutzen.
Darüber hinaus beziehen sich Variablen in einigen Fällen auf Werte, die an Punktpositionen gemessen wurden. In Variablen, die statistische Annahmen verletzen, können räumliche Trends und räumliche Autokorrelationen auftreten. Die geografisch gewichtete Regression ist die einzige Methode, die sich mit solchen Daten befasst.
Lineare Regressionsanalyse
Bei der linearen Regression ist die abhängige Variable Y ein Merkmalichist eine lineare Kombination von Parametern. Beispielsweise wird in einer einfachen linearen Regression eine unabhängige Variable, x, verwendet, um n-Punkte zu modellierenichund zwei Parameter β0 und β1.
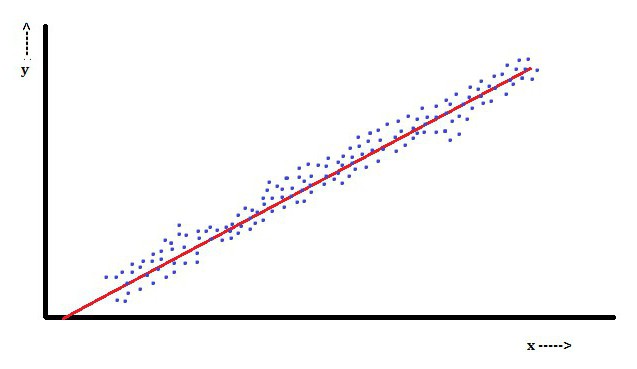
Bei der multiplen linearen Regression gibt es mehrere unabhängige Variablen oder deren Funktionen.
Mit einer Zufallsstichprobe aus einer Grundgesamtheit können anhand ihrer Parameter Beispiele für ein lineares Regressionsmodell erhalten werden.
In dieser Hinsicht ist die Methode der kleinsten Quadrate die beliebteste. Mit ihr werden Parameterschätzungen erhalten, die die Summe der quadratischen Residuen minimieren. Diese Art der Minimierung (die für eine lineare Regression charakteristisch ist) dieser Funktion führt zu einem Satz normaler Gleichungen und einem Satz linearer Gleichungen mit Parametern, die gelöst werden, um Parameterschätzungen zu erhalten.
Unter der weiteren Annahme, dass sich der Fehler der Grundgesamtheit normalerweise ausbreitet, kann der Forscher diese Schätzungen von Standardfehlern verwenden, um Konfidenzintervalle zu erstellen und Hypothesen über seine Parameter zu testen.
Nichtlineare Regressionsanalyse
Ein Beispiel, bei dem die Funktion in Bezug auf die Parameter nicht linear ist, gibt an, dass die Summe der Quadrate unter Verwendung einer iterativen Prozedur minimiert werden sollte. Dies führt zu vielen Komplikationen, die die Unterschiede zwischen linearen und nichtlinearen Methoden der kleinsten Quadrate bestimmen. Folglich sind die Ergebnisse der Regressionsanalyse nach der nichtlinearen Methode manchmal nicht vorhersehbar.
Berechnung von Leistung und Stichprobengröße
Hier gibt es in der Regel keine konsistenten Methoden hinsichtlich der Anzahl der Beobachtungen im Vergleich zur Anzahl der unabhängigen Variablen im Modell. Die erste Regel wurde von Good und Hardin vorgeschlagen und sieht wie folgt aus: N = t ^ n, wobei N die Stichprobengröße ist, n die Anzahl der unabhängigen Variablen ist und t die Anzahl der Beobachtungen ist, die erforderlich sind, um die gewünschte Genauigkeit zu erzielen, wenn das Modell nur eine unabhängige Variable hat. Ein Forscher erstellt beispielsweise ein lineares Regressionsmodell mit einem Datensatz, der 1000 Patienten enthält (N). Wenn der Forscher entscheidet, dass fünf Beobachtungen erforderlich sind, um die Linie (m) genau zu bestimmen, beträgt die maximale Anzahl unabhängiger Variablen, die das Modell unterstützen kann, 4.
Andere Methoden
Obwohl die Parameter des Regressionsmodells normalerweise mit der Methode der kleinsten Quadrate geschätzt werden, gibt es andere Methoden, die viel seltener verwendet werden. Dies sind beispielsweise die folgenden Methoden:
- Bayes'sche Methoden (z. B. Bayes'sche lineare Regressionsmethode).
- Prozentuale Regression, die für Situationen verwendet wird, in denen eine Reduzierung der prozentualen Fehler als geeigneter erachtet wird.
- Die kleinsten absoluten Abweichungen, die bei Ausreißern stabiler sind und zu einer quantilen Regression führen.
- Nichtparametrische Regression, die eine Vielzahl von Beobachtungen und Berechnungen erfordert.
- Die Entfernung der Lernmetrik, die auf der Suche nach einer signifikanten metrischen Entfernung in einem bestimmten Eingaberaum untersucht wird.
Software
Alle wichtigen statistischen Softwarepakete werden mithilfe der Regressionsanalyse der kleinsten Quadrate ausgeführt. Einfache lineare Regression und multiple Regressionsanalyse können in einigen Tabellenkalkulationsanwendungen sowie in einigen Taschenrechnern verwendet werden. Obwohl viele statistische Softwarepakete verschiedene Arten von nichtparametrischer und zuverlässiger Regression ausführen können, sind diese Methoden weniger standardisiert. Unterschiedliche Softwarepakete implementieren unterschiedliche Methoden. Für den Einsatz in Bereichen wie Untersuchungsanalyse und Neuroimaging wurde eine spezielle Regressionssoftware entwickelt.






